Throughout this moment we obtained an incredible amount of experience and also proficiency in web information removal. Internet scratching is everything about the information - the information fields you want to draw out from details sites. With scratching you typically know the target internet sites, you might not know the certain page Links, but you know the domains at least. One valuable package for web scratching that you can discover in Python's conventional collection is urllib, which contains tools for collaborating with URLs. Particularly, the urllib.request module contains a feature called urlopen() that you can use to open an URL within a program. The Web hosts probably the greatest resource of info in the world.
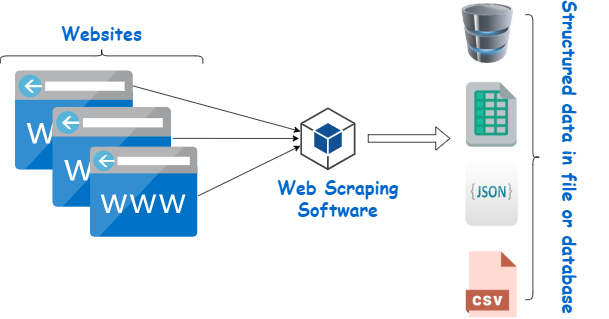
- In a very first exercise, we will download and install a solitary website from "The Guardian" as well as remove text together with appropriate metadata such as the post day.
- However after reviewing this post, we hope you'll be clear concerning the context, the points of distinction, as well as the use of both.
- This is something that deserves its own post, but also for now we can do fairly a lot.
- Usually, this is a JSON documents, yet it can also be saved in other styles like a succeed spreadsheet Python libraries for web scraping or a CSV file.
This command creates a new project with the default Scrapy job folder framework. To run our spider, simply enter this command on your command line. A standard spider can be built following the previous design representation.
Application Of Web Scuffing:
Although they may appear to generate the exact same outcomes, the two techniques are somewhat different. Both of them are required for the recovery of data, however the procedure entailed and also the sort of info asked for vary in several ways. Data creeping digs deep into the Web to recover data.
Is it legal to crawl data?
Web scuffing and also crawling aren't prohibited by themselves. Besides, you can scratch or crawl your very own site, without a hitch. Start-ups enjoy it due to the fact that it''s an economical and also effective way to collect data without the demand for collaborations.
Selenium logoBecause of its capability to make JavaScript on a web page, Selenium can aid scrape dynamic websites. This is a helpful attribute, considering that several modern-day sites, specifically in ecommerce, usage JavaScript to load their material dynamically. Selenium is largely an internet browser automation tool established for web testing, which is also located in off-label usage as a web scrape. It makes use of the WebDriver protocol to manage a headless web browser and also execute actions like clicking switches, completing kinds, and also scrolling. Analyzing, on the other hand, suggests assessing and also transforming a program into a format that a runtime atmosphere can run. Many thanks to Node.js abilities, the JavaScript community has a range of very efficient internet scratching collections such as Got, Cheerio, Puppeteer, and Playwright.
Crawlee
Proceeding with the previous example, when you look for internet crawling vs. internet scuffing, the search engine creeps every one of the web's websites, consisting of photos and also videos. Online search engine make use of internet crawlers to creep all web pages by following the web links embedded on those web pages. Web spiders discover brand-new links to other URLs as they crawl pages and also add these discovered links to the crawl queue to creep following.
Forget Milk and Eggs: Supermarkets Are Having a Fire Sale on Data ... - The Markup
Forget Milk and Eggs: Supermarkets Are Having a Fire Sale on Data ....
Posted: Thu, 16 Feb 2023 08:00:00 GMT [source]
The previous chapter showed different approaches of crawling with web sites as well as finding new web pages in an automatic way. Nonetheless, I believe that the power and also relative adaptability of this method more than makes up for its real or perceived imperfections. However, the information design is the underlying foundation of all the code that utilizes it. A bad choice in your design can easily cause troubles composing and also keeping code down the line, or trouble in extracting as well as effectively making use of the resulting data.
Scuffing Of Vibrant Websites
Although the applications of web spiders are nearly unlimited, huge scalable spiders often tend to fall into among a number of patterns. By learning these patterns and also recognizing the scenarios they put on, you can greatly improve the maintainability as well as robustness of your internet crawlers. Currently we can iterate over all URLs of tag overview pages, to gather more/all web links to articles identified with Angela Merkel. We repeat with a for-loop over all Links and append results from each solitary link to a vector of all web links. Currently, links consists of a listing of 20 hyperlinks to solitary write-ups identified with Angela Merkel. HTML/ XML objects are an organized representation of HTML/ XML source code, which enables to draw out solitary components (headlines e.g.
Our bot right here defines a Crawler course with a couple of helper methods and afterwards continues by instantiating the class with our IMDb beginning URL as well as calling its run() technique. For this, explore the link patterns of the page as well as check out the resource code with the 'check component' functionality of your web browser to find suitable XPATH expressions. To ensure that we get the dynamically provided HTML content of the internet site, we pass the original source code dowloaded from the link to our PhantomJS session first, and the usage the rendered resource. Import.ioImport.io is a feature-rich data mining tool collection that does a lot API Integration Services of the effort for you. " records that can inform you of updates to specified websites-- ideal for extensive competitor analysis.
And also, it permits advanced programming making use of REST API the user can connect straight with the Mozenda account. It provides the Cloud-based service and also turning of IPs as well. Next you'll use Floki to extract the information from the reaction. There hasn't been any type of parsing logic implemented in this fundamental example, so it returns a vacant Crawly.ParsedItem structure. In the following section of this tutorial, you'll utilize Floki to remove the information from the feedback.
https://maps.google.com/maps?saddr=433%20Yonge%20St%202nd%20Floor%2C%20Toronto%2C%20ON%20M5B%201T3%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
This is simple with Pandas given that they have a simple function for checking out JSON right into a DataFrame. Up until now we have actually presumed elements exist in the tables we scraped, however it's constantly a good concept to program scrapers in method so they do not damage when an aspect goes missing out on. Keep in mind, we've already evaluated our parsing above on a web page that was cached in your area so we understand it functions. You'll intend to make certain to do this prior to making a loop that performs requests to stop having to reloop if you neglected to analyze something. Obtaining the web link was a bit different than simply choosing a component.
Meta's new Twitter rival app Threads gets 10 million sign-ups within ... - Charleston Post Courier
Meta's new Twitter rival app Threads gets 10 million sign-ups within ....
Posted: Thu, 13 Jul 2023 02:00:55 GMT [source]
What is the distinction between scrapping and crawling?
Web scraping aims to extract the data on website, as well as internet crawling purposes to index and locate web pages. Internet crawling includes adhering to links completely based on links. In comparison, web scuffing suggests writing a program computer that can stealthily gather information from several sites.